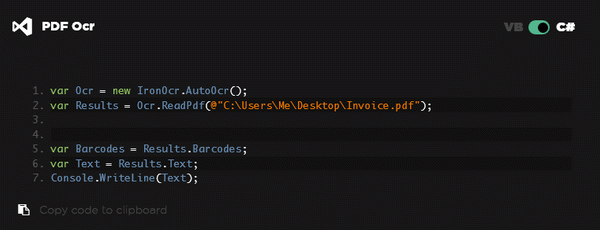
Text recognition is beginning to have an increasing presence in the programming scene, especially in the context of automation and efficiency increase. IronOCR - The VB.NET Library was built in order to allow users who work on the .NET platform to recognize and read text from PDF and image content. Basically, it will convert the images to text output and it also offers an extra facility, which provides barcode and QR code reading, with automated return.
The class which allows developers to benefit from the text reading capabilities is Auto OCR, which needs a single line of code. Furthermore, advanced support is also offered, which corresponds to the Advanced OCR class.
PDF encryption is not an issue, since the library supports reading text from documents with such characteristics. Multithreading is employed when performing reads from PDF pages that are using a single thread per page, in order to ensure a smooth and efficient process.
The real-world scanned images which might present imperfections or blemishes in the form of noise or skewing are covered, since the library is equipped with an automated detection module that accounts for and corrects such imperfections, yielding detection accuracy of more than 95%, according to the developer.
Daniel
salamat sa inyo para sa keygen
Reply
Brendon
Merci beaucoup!
Reply
Ramon
thank you
Reply