ASKY makes it easier for you to handle large data sets inside CSV files, providing functions that make it resemble more advanced database management software. This application can detect and isolate misaligned records, query large CSV files and manage fields in an easy manner, regardless of the file delimiter.
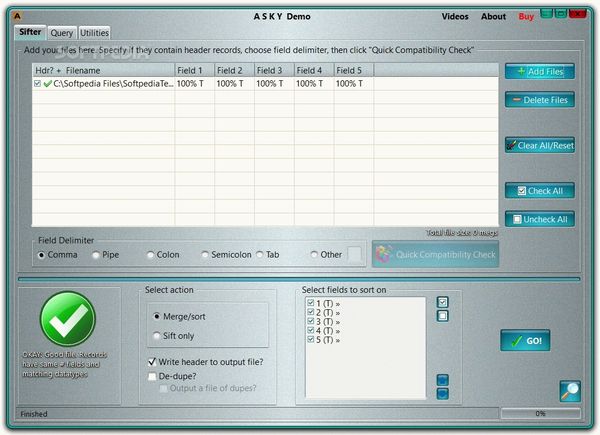
ASKY organizes all its functions into three different tabs. The first tab is dedicated to the Sifter, a tool that can analyze the data inside CSV files and find misaligned records, comparing them to a specific benchmark file of your choice. Therefore, if you own a file that comprises fields that are not lined up or duplicate fields, ASKY can easily take care of these issues for you.
Hovering the file names opens small popup windows where you can preview the data. This function is quite useful, as you can easily make sure the right file is selected. ASKY supports text and CSV files with and without headers, with various field separators: comma, pipe, colons, tabs and semi-colons.
While the Sifter in ASKY finds misaligned records, the utilities the application provides can fix them up so they can be easily inserted back into the original file. ASKY can easily move and replace data, delete existing fields or add new ones, or change the order of the fields in the file.
It also comes with an integrated file splitter and text replacing capabilities. Furthermore, it can easily filter data and change the formats of the date and the time for certain records.
Aiming to provide database-like functionality, ASKY also brings to the table a query tool, allowing you to easily find records that match certain rules of your choice. It enables you to specify the filtering criteria and sort the selected records afterwards.
ASKY enables you to use advanced tools on your regular CSV files, providing a way to benefit from the features of database management software without having to use SQL. It can take care of fields and records that don’t match the format of a user-defined benchmark file and query CSV files, providing the means to handle data sets in CSV files without too much hassle.
Sávio
спасибі за серійник для ASKY
Reply
Giulio
grazie mille per il serial del ASKY
Reply
Tiziano
grazie mille per il serial del ASKY
Reply
Donald
grazie mille per il patch del ASKY
Reply